
언어 전공자의 NLP 로그
COMET: A Neural Framework for MT Evaluation 본문
논문 출처 : https://aclanthology.org/2020.emnlp-main.213/
COMET: A Neural Framework for MT Evaluation
Ricardo Rei, Craig Stewart, Ana C Farinha, Alon Lavie. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
aclanthology.org
문제 의식
- 기존 메트릭은 번역 모델의 생성문 (가설)과 사람의 번역 (참조) 사이의 유사도를 측정하는 방식으로 MT의 질을 평가했다. n-gram 기반의 단어 매칭 수를 측정하는 간단한 방법은 BLEU, METEOR처럼 가볍고 빨라서 많이 사용됐다.
- MT 모델의 퀄리티가 향상된 것과 대비되게 평가 영역은 상대적으로 뒤쳐져 있다. (2019 WMT에서 MT 모델은 153개 제출, Metric은 24개 제출, 그 중 절반이 QE 변형)
- => 현 메트릭은 segment 단위에서 사람의 판단을 반영하지 못하고, 성능 좋은 MT 시스템과 차별점을 두지 못하고 있다.
해결 방안
- COMET의 키워드는 1) 다국어 학습 기반, 2) DA, HTER, MQM 기준 메트릭 등 사람의 판단을 예측하는 모델
- 참조 번역문 없이도 사람의 판단을 잘 반영하는 QE에 영감을 받아, 평가 모델에도 원문을 포함시킴 (기존의 MT 평가 메트릭은 참조 번역만 사용) ... 그래서 cross-lingual. 다국어 임베딩 스페이스에서 3개 입력 정보를 모두 활용할 수 있다.
- Estimator와 Translation Ranking model : 서로 다른 학습 목표를 가진 두 모델
- Estimator : 퀄리티 스코어를 예측하는 회귀 모델
- Translation Ranking : "더 나은" 가설과, 이에 매칭되는 원문/참조문과의 거리를 최소화하는 모델
- 모델 구조
- cross-lingual encoder : BERT, XLM, XLM-RoBERTa 중 마지막을 인코더 모델로 사용 (MLM 기반 사전학습 모델), 임베딩을 사용해 원문, 모델 생성 가설, 참조문을 공유 피쳐 공간에 맵핑함
- pooling layer : 대개 인코더의 마지막 레이어만 쓰는데, 다양한 레이어에 각기 다른 정보들이 숨어 있고, 마지막 레이어만 쓰면 오히려 성능 떨어짐. 그러니까 각 레이어를 어텐션 메커니즘을 이용해 정보를 풀링하자
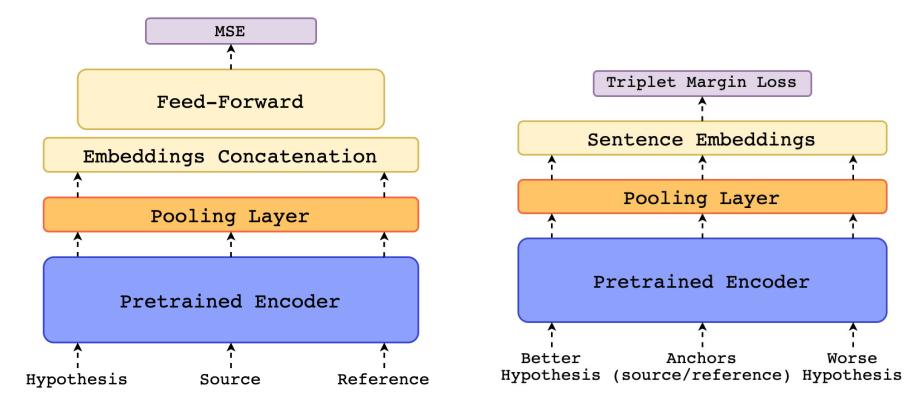
- Estimator model : 결과적으로 '사람이 평가한 점수'를 예측하는 회귀 모델. source, hypothesis, reference로부터 각각 encoding된 embedding을 출력하고, 이 embedding이 pooling layer를 지나면서 각각의 segment에 대한 문장 임베딩이 생성됨. 이를 하나의 벡터로 concat하여 feed-forward regressor로 내보내고, 이 값과 정답 간의 MSE를 목적 함수로 학습함.
- 하나의 벡터로 concat하는 과정은 $x=[h;r;h⊚s;h⊚r;|h−s|;|h−r|]$로 나타낼 수 있다.
- 주의할 점은, concat 시점에서 source의 임베딩은 빠진다는 것. (추가해도 별로 영향이 없었음) Zhao et al. (2020)에 따르면 cross-lingual 모델들이 다국어에 adapt한 것은 맞지만, 언어간 피처 스페이스 정렬이 형편없다고 함.
- 그렇지만 s를 $h⊚s,|h−s|$의 형태로 반영을 하니 성능이 분명 향상되었다고 주장.
- Translation Ranking model : 기존 source와 reference를 anchor로 삼고, 좋은 가설과 나쁜 가설을 추가하여 4개의 segment를 받게 됨. 마찬가지로 각각 encoding하고 pooling해서 최종적으로 triplet margin loss를 계산, 최종적으로 "좋은" 가설과 "anchor" 사이의 거리를 최소화하도록 학습한다.
- $x=(s,h+,h−,r)$을 튜플 형태로 입력하고, 이 x를 이후 인코더와 풀링 레이어에 넣으면 각 segment에 대한 문장 임베딩 X가 나온다.
- ${s,h+,h−,r}$ 형태의 임베딩으로 triplet margin loss를 구한다.
- $L(X)=L(s,h+,h−)+L(r,h+,h−)$, 이때 $L(s,h+,h−)=max{0,d(s,h+)−d(s,h−)+ϵ}$
- $d(u,v)$는 벡터 u와 v 사이의 유클리드 거리를 의미하고, $ϵ$은 margin이다. 이를 통해 학습하게 되면 anchor와 나쁜 가설의 거리가 anchor와 좋은 가설의 거리보다 최소 $ϵ$만큼 커지도록 (좋은 번역에 가까워지도록) 최적화할 수 있다.
- 추론 단계에서는 하나의 번역문 $h^$만을 받게 되는데, 이때는 거리를 계산하기 위해 조화 평균을 이용, $f(s,h^,r)=2∗d(r,h^)∗(s,h^)d(r,h^)+d(s,h^)$를 산출하고, 다음 식으로 최종 점수를 반환한다. $f^(s,h^,r)=11+f(s,h^,r)$. (이론적으로 s, h, r 사이의 거리가 0이면 점수가 1일 것이고, 거리가 멀수록 점수는 0에 수렴할 것이다.)
- 모델 실험
- QT21, 2017-2019 WMT DARR, MQM 코퍼스로 평가해보자.
- QT21은 IT나 생명과학 도메인에 관해 생성한 공개 데이터셋. s, h, r에 추가로 후처리 번역 결과도 포함. HTER을 직접 계산하고 최종적으로 $D={si,hi,ri,yi}n=1N$을 구성함. (즉, 라벨은 HTER 점수임)
- WMT DARR : 2017-2019 자료를 매년 $D={si,hi+,hi−,ri}$$로 구성.
- MQM은 unbabel의 내부 정보로, CS 챗 메시지에 주석을 닮. 영어는 항상 s 였음. 이 MQM 점수는 '문체', '유창성', '정확도'를 기준으로 -무한~100 사이로 측정된다. $MQM=100−IMinor+5∗IMajor+10∗ICritSentenceLength∗100$ I는 각각 사소한 오역, 중대한 오역, 치명적인 오역의 수로, HTER이나 DA보다 더 세부적인 기준으로 평가했다고 함. 본 실험에서는 100으로 나누고 소숫점은 버려 점수를 0~1으로 구성함.
- Estimator : COMET-HTER (QT21), COMET-MQM (MQM)
- Translation Ranking : COMET-RANK (WMT DARR)
- QT21, 2017-2019 WMT DARR, MQM 코퍼스로 평가해보자.
평가
- 평가 지표는 잘된 번역에 더 높은 점수를 주는지를 확인하기 위해 $τ=일치−불일치일치+불일치$로 계산.
- from English to X는 확연하게 COMET이 앞서나갔지만, to English는 살짝...애매?
- to English에서 MQM의 경우 영어를 target으로 하는 번역문을 넣지 않았는데도 꽤 좋은 결과가 나왔다며, 이를 학습 과정에 source를 넣었기 때문에 "zero-shot" 능력이 향상된 것이라고 주장한다.
- 영어를 s와 t 모두에 포함시키지 않고 WMT19 DARR에 실험했을 때는 COMET이 근소한 차이로...? 가장 우수했다.
- Source를 넣은게 정말 도움이 되었냐?
- ablation study를 해보니, ref만 넣은 모델보다 src를 같이 넣은 모델의 성능이 유의미하게 상승했다.
한계점
- 연구자들은 한계점으로 사전학습 모델의 사용이 파라미터 수와 추론 시간때문에 비교적 무겁다는 점을 지적한다.
- 또한 COMET-RANK 모델이 추론 단계에선 source와 reference에 다르게 가중치를 두지만, 학습 손실 함수에서는 동일하게 다루고 있다며 이 점을 추가로 조사한다고 한다.
- 개인적으로는 Table 3에서 성능 지표라고 제시한 부분에서 의문점이 들었는데, 이게 정말 baseline보다 좋아졌다고 볼 수 있는지 의문이 들었다. 일부 지표에서는 심지어 성능 하락이 관찰되기도 하고, 각 언어쌍마다 증가폭이 제각각인데, 그 함의가 궁금하다.

- 동시대 다른 metric과의 차이점은 source를 사용한 cross-lingual 학습 방식을 차용했다는 점인데, 증가폭이 그렇게 드라마틱하지는 않았던 것 같다.
궁금증
- What is segment-level in terms of linguistics?
단어의 의미를 바꿀 수 있는 최소 단위, 즉 cat, pat, mat의 c, k, m 등. 발화의 최소단위라고 한다. 강세, 톤 등 음성적인 요소들도 포함. 음성학적 개념. 자음, 모음 등
그럼 Morpheme이랑은 어떻게 다른가? morpheme은 의미의 최소 단위임. 의미론적/문법적 기능을 수행함.
그럼 Phoneme이랑은 어떻게 다른가? phoneme은 추상적인 개념으로, 소리 그 자체를 칭함.
그럼 이 논문에서 사용하는 segment는 위 의미가 맞나?
Human judgements of MT quality usually come in the form of segment-level scores, such as DA, MQM and HTER.
Finally, as in (Reimers and Gurevych, 2019), we apply average pooling to the resulting word embeddings to derive a sentence embedding for each segment.
보통 DA 등에서 점수를 매기는 단위 (입력값)는 문장쌍이다. DA라면 to-English로 번역된 hypothesis와 reference를 보는 것이겠고, 본 논문에서 얘기하는 cross-lingual embedding은 여기에 source까지 추가한 문장쌍이 segment가 된다. 즉, 후자의 for each segment는 source, hypothesis, reference를 의미하는 것으로 보임. 이는 Figure 1의
The source, hypothesis, and reference are independently encoded using a pretrained cross-lingual encoder
라는 표현과도 일맥상통함.
- What is Quality Estimation?
본 논문에서는 QE를 reference-less MT evaluation이라고 칭하고 있다. 기존의 BLEURT의 한계를 지적하면서 'DA 최적화에 중점을 두고 있는데, 우리가 알기로 DA는 평가자가 부족해서 꽤나 노이지하다'고 얘기하는데, 이러한 참조가 필요 없는 평가라면 좀더 강건한 평가가 가능할 것으로 보인다. 보통 HTER를 기반으로 한 회귀 학습을 진행하는듯 보임.
'논문 읽기' 카테고리의 다른 글
| Large Language Models are not fair Evaluators (3) | 2024.03.01 |
|---|---|
| GPTScore: Evaluate as You Desire (0) | 2024.03.01 |
| BLEURT: Learning Robust Metrics for Text Generation (2) | 2024.02.29 |
| BARTScore: Evaluating Generated Text as Text Generation (2) | 2024.02.29 |
| Multiloop Incremental Bootstrapping for Low-Resource Machine Translation (2) | 2024.02.29 |
