
언어 전공자의 NLP 로그
Transformer: Attention is All you need 본문
논문 출처 : https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
0. Abstract
- 당시 시퀀스 모델은 RNN 및 CNN 형태가 주도적이었고, 여기에 attention 메커니즘을 더했을 때 성능이 향상됨을 확인할 수 있었다.
- 이 attention 메커니즘에 착안하여 RNN/CNN 구조를 제거한 Transformer 모델을 제안한다.
- 행렬곱을 기반으로 한 병렬화로 처리 속도를 향상시키면서 개선된 BLEU 점수의 기계 번역 모델을 만들어낼 수 있었다. (SOTA)
1. Introduction
- RNN, LSTM, GRN 등 순환형 모델은 시퀀스를 하나하나 넣어가며 입력을 수행하기 때문에 메모리/속도 측면에서 비효율적이다.
- Attention 가중치를 반영하여 성능을 개선한 모델들도 recurrent한 구조를 띄고 있다.
- 이에 본 논문에서는 recurrence를 제거하고, 인풋과 아웃풋의 전역적인 의존 관계를 이끌어내는 어텐션 메커니즘만으로 설계한 모델을 제안한다.
2. Background
- Self-attention이란 자기 자신에 대한 어텐션을 학습하도록 하여 하나의 시퀀스와 다른 위치 정보에 대한 레퍼런스를 학습함으로써 가중치를 부여하는 방법이다.
- Transformer는 이러한 self-attention에 기반한 모델이다.
3. Model Architecture
- 시퀀스 변형 모델은 대부분 encoder-decoder 구조로 구성되어, 인풋 시퀀스 x를 연속적인 형태의 z로, 그리고 이 z를 디코더에 입력해 최종 결과물은 y를 출력하는 방식이다. Transformer 역시 이러한 구조를 차용하지만, recurrent한 정보를 활용하지 않고 한번에 시퀀스에 대한 정보를 제공한다는 점이 차별점이다.
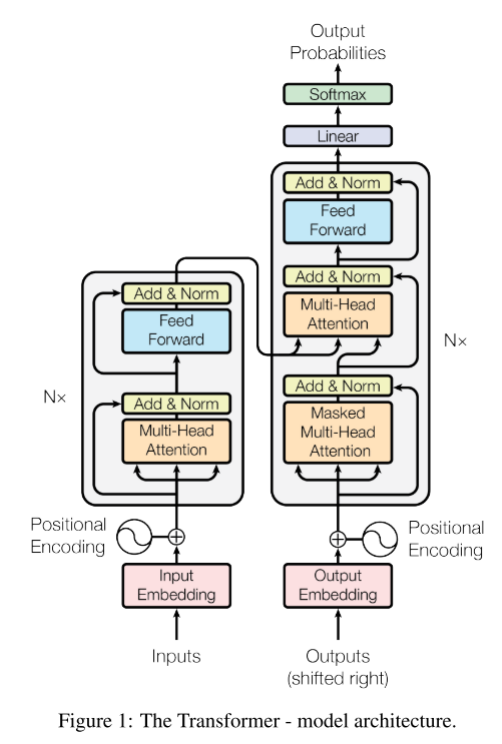
- 인코더
- N=6번의 attention 추출 과정을 거치고, 그 최종 결과를 디코더의 중간에 반영시켜준다.
- 레이어 정규화 이후 두 번의 잔여 학습을 수행한다.
- 아웃풋의 최종 디멘션은 512로 설정한다.
- 디코더
- 마찬가지로 N=6개의 layer를 생성하고, masked self-attention을 수행한 뒤, 인코더의 아웃풋을 Q/K로 받아 이를 출력에 반영한다.
- 어텐션
- query를 key-value에 맵핑하는 과정은 특정 단어를 선택하는 과정에서 어떠한 단어가 가장 큰 영향을 미쳤는지를 확인하는 과정이다.
- 이 attention 연산은 행렬곱으로 이루어진다.
- Scaled Dot-Product Attention
- 병렬화를 가능하게 하는 연산으로, 스케일링 / 마스킹 / 소프트맥스를 거쳐 최종적으로 $dmodelh$의 차원을 가진 h개의 attention 행렬이 만들어지게 된다.
- 이 h개의 행렬을 다시 합쳐서 원래의 차원을 복구해준다.
- Attention의 수행 위치
- 인코더-디코더 어텐션 : 번역 task를 예로 들면, 원천어의 단어와 도착어의 단어 간의 attention 관계를 살핌으로써 매칭되는 번역어를 찾는 과정이다.
- 인코더 self-attention : 원천어의 단어들 간의 문맥 정보를 살핀다.
- 디코더 self-attention : 도착어의 단어들 간의 문맥 정보를 살핀다. 이때, 마스킹을 활용하여 앞에 나온 단어들만 살피도록 한다.
- Positional Encoding
- Recurrent한 sequence 구조를 포기했기 때문에 위치 정보를 별도로 임베딩 해주는 과정을 거친다.
- 주기 함수를 이용한 고정 위치 벡터를 활용할 수도 있고, 별도의 학습 가능 레이어를 활용할 수도 있다.
4. Why Self-Attention
- 연구자들이 본 self-attention 과정의 장점은 크게 세 가지이다.
- 계산 복잡도를 줄일 수 있다. ($n2∗d$ vs $n∗d2$)
- 병렬화가 가능하다.
- 장기 의존성 문제를 해결할 수 있다.
- 또한 실제 attention matrix를 시각화하여 번역 과정에서 어떤 단어를 참조했는지 확인할 수 있다.
5. Training
- 영어-독어 번역 문장쌍을 이용해 학습했다.
- Adam optimizer를 사용했다.
- Residual dropout을 적용했다.
- Label smoothing 기법을 사용했다.
6. Results
- 베이스 모델만으로도 번역에서 SOTA 결과를 얻을 수 있었다.
- Head의 수, 각 attention layer의 수, dropout 비율, positional embedding 등을 활용했을 때의 결과를 각각 실험하기도 했다.
- 구문 분석 (constituency parsing) 과제에도 활용할 수 있다.
7. Conclusion
- 전적으로 attention 메커니즘만으로 좋은 성능과 병렬화를 이루어 냈다.
- 기계 번역 뿐만 아니라 여러 과제에도 적용 가능성이 높은 모델 구조이다.